
Open source self-hosted Delta Sharing server
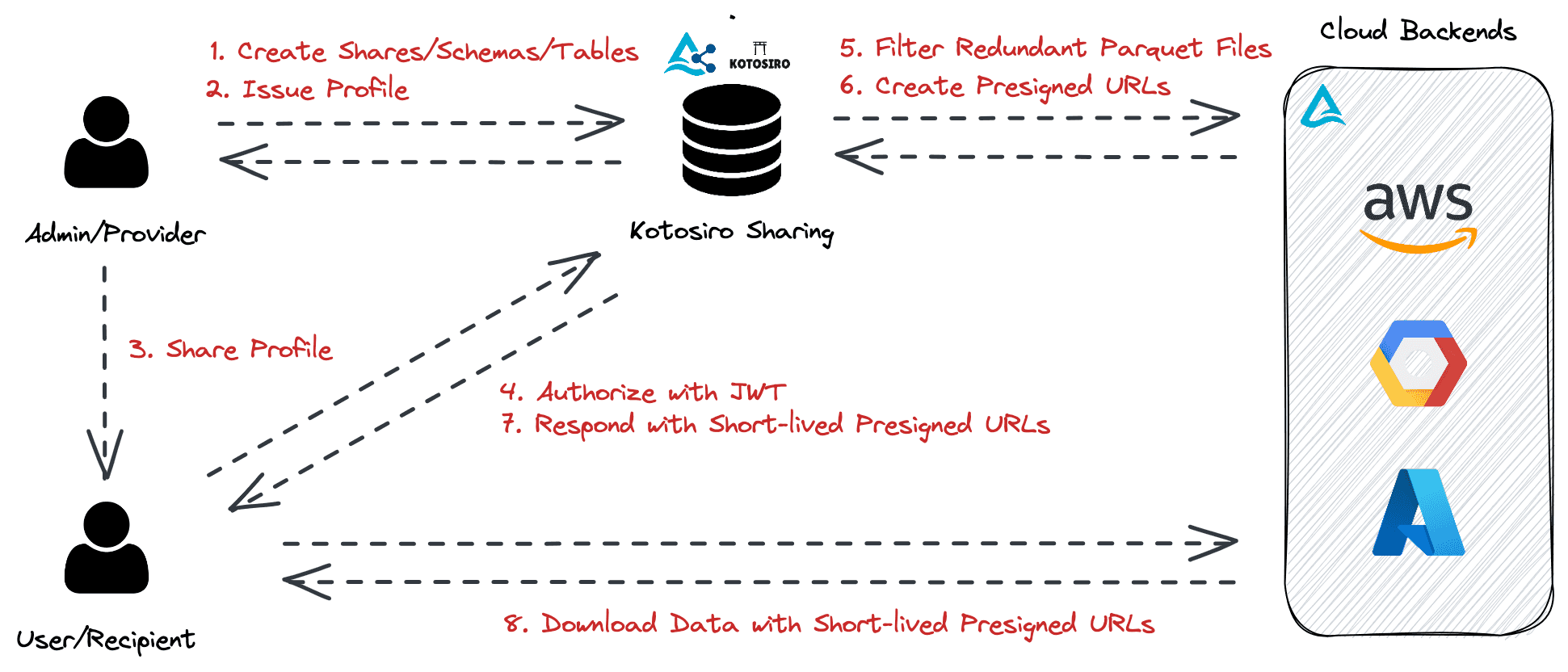
My name is Shingo, creator of Kotosiro Sharing. I am excited to announce the release of Kotosiro Sharing, a minimalistic Rust implementation of the Delta Sharing server aimed at helping engineers easily host their own Delta Sharing service. In this article, I will provide instructions on how to share your data with your colleagues who may have varying technical backgrounds, ranging from data engineers to business intelligence analysts, using self-hosted Kotosiro Sharing server. The instructions are fairly easy and straightforward, and you can easily share your data with colleagues who have different levels of technical expertise. The implementation is currently in the beta phase, and hence, it does not provide a GUI yet. However, this feature will be added in the near future. The following image depicts the system workflow. Let's walk through how Kotosiro Sharing works when you want to share precious data with your colleagues.
Delta Table Structure
You have historical data on avocado prices and sales volume in multiple US markets stored in your Delta table on AWS S3. Your colleague has come to your desk and asked if they could use the data for further data analytics. The structure of the table is as follows:
avocado-table
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ ├── 00000000000000000002.json
│ └── 00000000000000000003.json
├── part-00000-04d10a18-acde-4d66-bb3b-39f5d0feb689-c000.snappy.parquet
├── part-00000-c5135c42-2c15-4da5-8cd6-f0fc527dff9c-c000.snappy.parquet
├── part-00000-c6c1e092-bef3-41a0-8a05-826a33ecff6f-c000.snappy.parquet
└── part-00000-d7afaec2-4373-4865-ab48-e9f60495b41e-c000.snappy.parquet
Each parquet file is appended sequentially. Therefore, the table has four different versions.
Share Your Delta Tables via Kotosiro Sharing APIs
Log in to Kotosiro Sharing Server and Get the Admin Access Token
Now let's get started with the interesting part. As the owner of the data and administrator of your Kotosiro Sharing server, you need to log in to the system and obtain the admin access token. This token will enable you to create a share. Here's how you can obtain the token:
$ curl -s -X POST http://localhost:8080/admin/login \
-H "Content-Type: application/json" \
-d '{"account": "kotosiro", "password": "password"}' \
| jq '.'
{
"profile": {
"shareCredentialsVersion": 1,
"endpoint": "http://127.0.0.1:8080",
"bearerToken": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoia290b3Npcm8iLCJlbWFpbCI6ImtvdG9zaXJvQGVtYWlsLmNvbSIsIm5hbWVzcGFjZSI6ImFkbWluIiwicm9sZSI6ImFkbWluIiwiZXhwIjoxNjgxOTM3NzMyfQ.rVjA6S7EWq7CakpB0IHik0mvxl58ynZNxNM3a3RJibY",
"expirationTime": "2023-04-19 20:55:32 UTC"
}
}
Register a New Share
Next, you need to register a new share, which is simply a logical grouping used to share with recipients. For example, you can name your share share1. Note that this share is currently empty, meaning that you haven't added any data to it yet. Here's how you can create the share:
$ curl -s -X POST "http://localhost:8080/admin/shares" \
-H "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoia290b3Npcm8iLCJlbWFpbCI6ImtvdG9zaXJvQGVtYWlsLmNvbSIsIm5hbWVzcGFjZSI6ImFkbWluIiwicm9sZSI6ImFkbWluIiwiZXhwIjoxNjgxOTM3NzMyfQ.rVjA6S7EWq7CakpB0IHik0mvxl58ynZNxNM3a3RJibY" \
-H "Content-Type: application/json" \
-d '{ "name": "share1" }' \
| jq '.'
{
"share": {
"id": "78f84b5e-29e7-4adf-8df5-c40487a8da43",
"name": "share1"
}
}
Register a New Table
So far, so good. Now it's time to register the Delta table on AWS S3 to your Kotosiro Sharing service via the API. It's fairly simple like other operations. Just post a JSON data that specifies the S3 bucket object path to the Delta table, along with the table name. For example, you can name your table table1. Here's how you can register the table:
$ curl -s -X POST "http://localhost:8080/admin/tables" \
-H "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoia290b3Npcm8iLCJlbWFpbCI6ImtvdG9zaXJvQGVtYWlsLmNvbSIsIm5hbWVzcGFjZSI6ImFkbWluIiwicm9sZSI6ImFkbWluIiwiZXhwIjoxNjgxOTM3NzMyfQ.rVjA6S7EWq7CakpB0IHik0mvxl58ynZNxNM3a3RJibY" \
-H "Content-Type: application/json" \
-d '{ "name": "table1", "location": "s3://kotosiro-sharing-example/avocado" }' \
| jq '.'
{
"table": {
"id": "8a040c74-4505-44e5-aeda-9db662f338eb",
"name": "table1",
"location": "s3://kotosiro-sharing-example/avocado"
}
}
Register a New Table as a Part of schema1 in the share1
You have created a new share and registered a new table. Now, you need to associate the table with the share by creating a schema. To do this, you can register the table as part of, for example, the schema1 in share1. The API operation to register the table to the share is fairly straightforward. Here's an example of how to do it:
$ curl -s -X POST "http://localhost:8080/admin/shares/share1/schemas/schema1/tables" \
-H "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoia290b3Npcm8iLCJlbWFpbCI6ImtvdG9zaXJvQGVtYWlsLmNvbSIsIm5hbWVzcGFjZSI6ImFkbWluIiwicm9sZSI6ImFkbWluIiwiZXhwIjoxNjgxOTM3NzMyfQ.rVjA6S7EWq7CakpB0IHik0mvxl58ynZNxNM3a3RJibY" \
-H "Content-Type: application/json" \
-d '{ "table": "table1" }' \
| jq '.'
{
"schema": {
"id": "62bf785c-1764-4953-9986-a6708996e72c",
"name": "schema1"
}
}
Issue a New Recipient Profile
This is the final and most important step in sharing your Delta table with your colleagues. You need to issue a new recipient profile, which contains the necessary credentials for your colleagues to access the shared data. The resulting profile JSON is a credential, so you must share it securely with your colleagues. As an administrator, you are responsible for ensuring that the profile is shared only with authorized recipients. Here's how you can issue the profile:
$ curl -s -X GET "http://localhost:8080/admin/profile" \
-H "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoia290b3Npcm8iLCJlbWFpbCI6ImtvdG9zaXJvQGVtYWlsLmNvbSIsIm5hbWVzcGFjZSI6ImFkbWluIiwicm9sZSI6ImFkbWluIiwiZXhwIjoxNjgxOTM3NzMyfQ.rVjA6S7EWq7CakpB0IHik0mvxl58ynZNxNM3a3RJibY" \
-H "Content-Type: application/json" \
| jq '.'
{
"profile": {
"shareCredentialsVersion": 1,
"endpoint": "http://127.0.0.1:8080",
"bearerToken": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJuYW1lIjoia290b3Npcm8iLCJlbWFpbCI6ImtvdG9zaXJvQGVtYWlsLmNvbSIsIm5hbWVzcGFjZSI6ImFkbWluIiwicm9sZSI6Imd1ZXN0IiwiZXhwIjoxNjgxOTM3ODA1fQ.Pwqa5ylTDnjyivNsyNTi0QNR1oKuHJhCPPxWiznomRE",
"expirationTime": "2023-04-19 20:56:45 UTC"
}
}
Create Sharing Client
From now on, you are the recipient of the shared Delta table. To open the shared Delta table as a pandas dataframe, you, as the recipient of the shared Delta table, need to first install the delta-sharing package. After installing the package, you can create a delta_sharing.SharingClient object using the shared profile. This will allow you to access the shared Delta table.
import delta_sharing
profile = "../../creds/profile.json"
client = delta_sharing.SharingClient(profile)
List Tables
Let us verify that we can access the shared table properly. The following script retrieves a list of all tables shared by the share provided by your colleague:
client.list_all_tables()
[Table(name='table1', share='share1', schema='schema1')]
Load Tables
Now it's time to access the shared data. The operation is incredibly simple: there's no need to prepare troublesome cloud service credentials, and you don't have to worry about what platform your colleague is using. All you have to do is specify the path to the table. A table path consists of the profile file path followed by # and the fully qualified name of a table: <share-name>.<schema-name>.<table-name>.
url = profile + "#share1.schema1.table1"
delta_sharing.load_as_pandas(url)
| row | date | average_price | total_volume | 4046 | 4225 | 4770 | total_bags | small_bags | large_bags | xlarge_bags | type | year | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2015-12-26 15:00:00 | 1.33 | 64236.62 | 1036.74 | 54454.85 | 48.16 | 8696.87 | 8603.62 | 93.25 | 0.0 | conventional | 2015 | Albany |
| 1 | 1 | 2015-12-19 15:00:00 | 1.35 | 54876.98 | 674.28 | 44638.81 | 58.33 | 9505.56 | 9408.07 | 97.49 | 0.0 | conventional | 2015 | Albany |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 18247 | 10 | 2018-01-13 15:00:00 | 1.93 | 16205.22 | 1527.63 | 2981.04 | 727.01 | 10969.54 | 10919.54 | 50.00 | 0.0 | organic | 2018 | WestTexNewMexico |
| 18248 | 11 | 2018-01-06 15:00:00 | 1.62 | 17489.58 | 2894.77 | 2356.13 | 224.53 | 12014.15 | 11988.14 | 26.01 | 0.0 | organic | 2018 | WestTexNewMexico |
18249 rows × 14 columns
SQL Expressions for Filtering
Great! Now you can access the desired data from the data lake. Suppose you are only interested in the data within the date range of 2016-01-01 and 2017-12-31. In this case, you can send SQL snippets as hints to the sharing server so that it filters out redundant Parquet files. Here's how you can request the desired Parquet files (As of April 24, 2023, this filter API is not public in the Python client library, so this code snippet are based on my local patch. I plan to create a pull request in the near future to add this filter API to the public release):
url = profile + "#share1.schema1.table1"
delta_sharing.load_as_pandas(
url,
predicateHints=['year >= 2016', 'year <= 2017']
)
| row | date | average_price | total_volume | 4046 | 4225 | 4770 | total_bags | small_bags | large_bags | xlarge_bags | type | year | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2016-12-24 15:00:00 | 1.52 | 73341.73 | 3202.39 | 58280.33 | 426.92 | 11432.09 | 11017.32 | 411.83 | 2.94 | conventional | 2016 | Albany |
| 1 | 1 | 2016-12-17 15:00:00 | 1.53 | 68938.53 | 3345.36 | 55949.79 | 138.72 | 9504.66 | 8876.65 | 587.73 | 40.28 | conventional | 2016 | Albany |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 11336 | 49 | 2017-01-07 15:00:00 | 1.18 | 14375.39 | 1327.98 | 2617.20 | 5.75 | 10424.46 | 10283.85 | 140.61 | 0.00 | organic | 2017 | WestTexNewMexico |
| 11337 | 50 | 2016-12-31 15:00:00 | 1.28 | 15307.87 | 867.66 | 3434.02 | 37.30 | 10968.89 | 10815.88 | 153.01 | 0.00 | organic | 2017 | WestTexNewMexico |
11338 rows × 14 columns
JSON predicates for Filtering
While the previous predicateHints using SQL filtering is handy, its logical expressiveness is a bit limited and it is recommended to use JSON filtering instead as per the official protocol specification. It should be noted that the SQL filtering method will be deprecated. Here's how you can request the desired Parquet files using JSON filtering(As of April 24, 2023, this filter API is not public in the Python client library, so this code snippet are based on my local patch. I plan to create a pull request in the near future to add this filter API to the public release):
url = profile + "#share1.schema1.table1"
delta_sharing.load_as_pandas(
url,
jsonPredicateHints={
"op": "and",
"children": [
{
"op": "greaterThanOrEqual",
"children": [
{"op": "column", "name": "year", "valueType": "int"},
{"op": "literal", "value": "2016", "valueType": "int"}
]
},
{
"op": "lessThanOrEqual",
"children": [
{"op": "column", "name": "year", "valueType":"int"},
{"op": "literal", "value": "2017", "valueType": "int"}
]
}
]
}
)
| row | date | average_price | total_volume | 4046 | 4225 | 4770 | total_bags | small_bags | large_bags | xlarge_bags | type | year | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2016-12-24 15:00:00 | 1.52 | 73341.73 | 3202.39 | 58280.33 | 426.92 | 11432.09 | 11017.32 | 411.83 | 2.94 | conventional | 2016 | Albany |
| 1 | 1 | 2016-12-17 15:00:00 | 1.53 | 68938.53 | 3345.36 | 55949.79 | 138.72 | 9504.66 | 8876.65 | 587.73 | 40.28 | conventional | 2016 | Albany |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 11336 | 49 | 2017-01-07 15:00:00 | 1.18 | 14375.39 | 1327.98 | 2617.20 | 5.75 | 10424.46 | 10283.85 | 140.61 | 0.00 | organic | 2017 | WestTexNewMexico |
| 11337 | 50 | 2016-12-31 15:00:00 | 1.28 | 15307.87 | 867.66 | 3434.02 | 37.30 | 10968.89 | 10815.88 | 153.01 | 0.00 | organic | 2017 | WestTexNewMexico |
11338 rows × 14 columns
Conclusion
I am really happy to announce the release of the Kotosiro Sharing project, and I want to thank you for reading so far. I hope you have enjoyed this short journey and have seen how Delta Sharing could change the game. What I really like about this idea is:
- The open and cloud-agnostic protocol.
- The ease of managing privacy, security, and compliance.
- Eliminating lagging and inconsistent data, as well as the need to email stale data around.
- The fact that it doesn't require technical expertise from recipients, as they only need to write a few lines of Python code.
The official open protocol specification is available here. I also welcome contributions to my Kotosiro Sharing project. Thanks for reading!